Wenn ein Program dass Gleitkommazahlen von einer oder in eine Textdatei liest, bzw. schreibt nicht mehr funktioniert, dann sollte man sich genauer mit LC_NUMERIC befassen. Dieser Artikel behandelt die Auswirkungen auf Qt- und reine C-Programme.
LC_NUMERIC ist Bestandteil der sogenannte locales, der Lokalisierungen (oder auch Regionalisierungen) auf einem System. Diese Lokalisierungen lassen sich sehr fein einstellen – bspw. LC_MONETARY für die Währung oder eben LC_NUMERIC für das Zahlenformat – aber auch zusammenfassend mittels LC_ALL. Setzt man bspw. LC_ALL=de_CH.UTF-8, dann wird diese Einstellung auf alle sublocales übertragen und für LC_MONETARY ist der Franken gesetzt, wenn auch das meiste andere ziemlich deutsch ist.
Ok, nun aber zum Zahlenformat – und um die Sache ein bischen zu beschleunigen, soll eine Textdatei mit folgendem Inhalt ausgelesen werden.
#Hallöle
33.456,78
33456.78
33,456.78
33,99
33.98
33.777
Um die Zahlen besser zu verstehen muss noch einmal ausgeholt werden. LC_NUMERIC legt zwei Parameter fest.
Den Dezimaltrenner und den Tausender-Trenner. Er wird folgendermassen gesetzt:
| Locale |
Dezimaltrenner |
Tausender-Trenner |
| en_US |
. |
, |
| de_DE |
, |
. |
| C |
. |
|
Das bedeutet, dass die deutsche Lokalisiserung genau andersherum als die US-Amerikanische ist. Die sog. C-Locale (auch POSIX-Locale genannt) kennt nur den Dezimaltrenner. Diese Locale ist als Rückfallebene gedacht.
Wie verhält sich nun ein Qt-Programm (Qt4), dass die o.g. Textdatei zeilenweise einliest und versucht den Text in Zahlen zu konvertieren? Zuerst einmal wird ein Testprogram unter der Umgebung LC_NUMERIC=de_DE.UTF-8 gestartet.
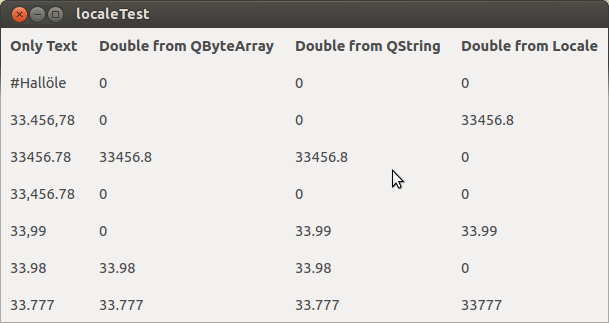
Die Erklärung ist überrasch komplex. Zuerst einmal muss festgestellt werden, dass Qt Programme generell LC_NUMERIC-aware sind. Dies wird dadurch erreicht, dass QCoreApplication
setlocale(LC_ALL,"");
aufruft und damit locales aus dem Environment dem Programm zur Verfügung gestellt werden (dies wird durch die doppelten Anführungszeichen erreicht). Dennoch werten nicht alle Qt-Methoden LC_NUMERIC aus.
QByteArray::toDouble()
ignoriert die gesetzte locale und benutzt immer die C-Locale.
QString::toDouble()
verhält sich am kompliziertesten. Es wird der Dezimaltrenner der gesetzten locale ausgewertet, nicht aber der Tausender-Trenner (die Gründe liegen in der Kompatibilität zu C, siehe später). Gleichzeitig wird die C-Locale immer als Fallback mitausgewertet. Bei Qt5 verhält sich übrigens QString::toDouble wie QByteArray::toDouble
QLocale::toDouble()
hingegen orientiert sich ausschliesslich an der gesetzten locale.
Zum Vergleich nun die Ausgabe unter dem Environment LC_NUMERIC=en_US.UTF-8
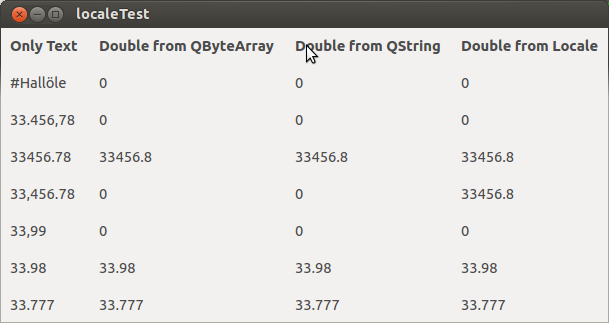
Interessant ist nun der Vergleich zu reinen C-Programme. Denn reine C-Programme mit ihren typischen Funktionen
printf/fprintf
scanf/fscanf
strtof
..usw. ignorieren standardmässig die gesetzte locale und stützen sich immer auf die C-Locale. Erst durch den schon oben genannten Aufruf von setlocale werden C-Programme locale-aware.
Werden allerdings C-Funktionen – bspw. aus einer Bibliothek – von einem Qt-Programm verwendet, sind sie automatisch locale-aware, da ja wie schon erwähnt QCoreApplication setlocale aufruft.
Dies ist eine große potentielle Fehlerquelle!
Um den Bogen zu QString::toDouble() nochmals zu spannen, sei erwähnt, dass C-Funktionen den Tausender-Trenner standardmässig ignorieren. Um z.B. printf zur Ausgabe des Tausender-Trenners bei Gleitkommazahlen zu zwingen, muss man
printf("Gezwungen zu %'f",myfloat);
einen Abostroph vor dem Formatierungszeichen einführen.
Zum Ausprobieren liegt das Qt Beispielprogramm sowie zwei plain C-Programme im diesem Archiv bei