Die Aufgabe lautet die UTF-8 BOM (0xEFBBBF) mittels eines Hexeditors in ein simples Textfile einzufügen.
Getestet wurden auf Ubuntu 12.04 verschiedene Tools – hier das Ergebnis:
1. hte (Konsolenhexeditor mit ncurses)
Leider ist die Integration von ncurses in die Ubuntu Welt – genauer gesagt in ein Gnome Terminal – nicht prickeld. Wesentliche Kommandos die mit der ALT Taste gesteuert werden wurden anstatt in das ncurses Programm an das darüberliegende Terminal übertragen, so dass ich es nicht schaffen konnte in den Edit Mode zu kommen. Ansonsten ist die grafische Representation des Byte-Codes ansprechend.
2. vi (mittels xxd)
Falls man mit vi -b ein File im binären Modus öffnet, kann man mit folgender Sequenz
:%!xxd
..Manipulation des Files
:%!xxd -r
die Datei ändern. Das Hinzufügen oder Entfernen von Bytes gelang mir auf Anhieb nicht. Mein Fazit: Für schnelle Manipulationen ideal, aber nur dafür.
3. okteta
Der KDE Hexeditor läuft selbstverständlich auch auf dem Ubuntu Unity Desktop. Was die Optionen der grafischen Representation anbelangt das beste Programm. Im Detail offenbaren sich – wie so oft unter KDE Schwächen. Bei der Characterdarstellung der Bytes sollte man sich auf einen rein lokalen 8-Byte Zeichensatz beschränken anstatt dem User vorzugauckeln, dass ein Byte eines Umlautes unter UTF-8 einem Character entspricht (bei der Byte-Sequenz C3B6 ‚ö‘ wird schon alleine C3 unter UTF-8 als ‚ö‘ dargestellt, zumindest in der Decoding Tabelle). Auch die Layout-Voreinstellungen der GUI sind nicht optimal.
4. bless
Das Mono-basierte Programm hat leider die Systembedingten Abhängigkeiten von allerhand Mono-Libraries.
Ansonsten wirkt das Programm aber sehr aufgeräumt und stringent. Von der Bedienung her das einfachste Programm – allerdings kann es nach der Manipulation nicht auf das geöffnete File zurückschreiben. Wer das versucht, bekommt folgende kryptische Fehlermeldung.
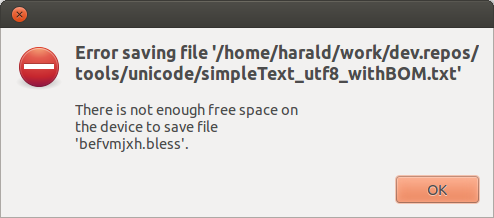
Fazit: Je nach Geschmack eignet sich okteta oder bless am Besten für diese Aufgabe